前言
性能是企业级应用十分注重的方面,我们都不想让打日志这个过程成为性能的瓶颈。对于小型应用,日志应用可能无法构成瓶颈,但如果是企业级有高并发的需求的工程,每秒调用几百甚至上千次的 log 方法,可想而知,对于磁盘读写来说是非常恐怖的。因此,为了提高日志系统的性能,我们引入 log4j 2 的异步日志(asyncLogger)功能。异步日志通过将打日志的逻辑和执行代码的线程解耦,使得打日志的逻辑有自己的专有线程,排除了日志的性能瓶颈问题。
众所周知,I/O 操作是程序中的性能杀手,因为 I/O 过程会不可避免地引入锁和线程等待,如果占用了程序进程,则会大量消耗程序的性能,因此,把日志逻辑分到其他线程上去操作,则可以大量释放主线程的资源以更高效地执行任务,而异步日志就是实现了这个功能,下面,就来讲讲异步日志系统的实现原理。
log4j 2 Async Logging 的实现原理
多线程日志系统(Multi-thread Logging)在 log4j2 的 async logging 之前就已经出现了,但是 log4j2 的 async logger 与传统异步日志的主要差异在于:logging 逻辑是如何被主线程分配到其他线程上去的。传统异步日志系统使用了 ArrayBlockingQueue 的数据结构,而我们知道,ArrayBlockingQueue 的源码中使用了全局锁:
1 | /** Main lock guarding all access */ |
来保证内部数据的一致性和可见性,而引入锁的同时就会引发阻塞和等待,因此,使用带有全局锁的数据结构将日志信息转交给专门的 I/O 相关线程并不是最优的方法。为了优化这一部分的性能损耗,log4j 2 中的 Async Logger 使用了一种不使用锁的线程信息交换库:LMAX-disruptor,实现了更高的吞吐量和更短的延迟。
LMAX Disruptor 解析
LMAX Disrutor 概述
LMAX Disruptor 的设计来自于 LMAX 公司的高性能的交易系统,其 Business Processor 模块单元(主从模式,防止一个模块单元挂掉)是一个单线程的事件驱动型系统,却可以实现 600 万次/秒的订单处理速度,而为了保证这个高效率的 Business Processor 可以高效运行,其输入事件处理单元需要有较强的处理能力,并且可以保证生成符合条件的输入事件,进入后续 Processor 进行处理。而 LMAX Disruptor 就诞生于这个输入事件处理单元(后面称为“单元”)中,根据文档中的说法,这个“单元”需要对传输线路中过来的信息有如下的功能:
- Replicator:复制多份,送到主从模式的各 Business Processor 中进行处理
- Unmarshaller:信息解析,以便后续处理器可以更方便地处理
- Journaller:将处理的事件打入日志,保证故障恢复过程
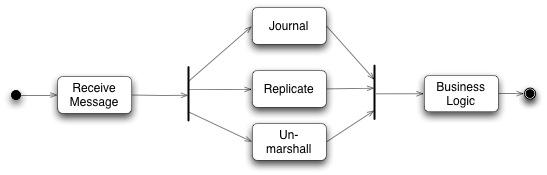
可以看到,这三个功能没有特定的顺序要求,你什么时候复制,什么时候打日志,什么时候解码都对后续的状态没有任何影响,因此,这样的特点天然适合于并行操作。而这三个功能可以抽象成为消息的消费者,图中 Receive Message 模块可以作为消息的生产者;这样一个天然的消息队列的模型就建立了。
LMAX Disruptor 数据结构选型
前面说到,LMAX Disruptor 的本质是一个生产者-消费者模式的消息队列。如果用类似于 ArrayBlockingQueue 这种数据结构作为消息队列的话,如果锁粒度太大,则会出现读写竞争,造成阻塞;如果锁粒度太小,则实现上难度太大,其实阻塞队列的实现在实测中也被发现阻塞情况耗费太多性能的情况。因此 LMAX Disruptor 选择了自己实现一个环形缓冲器的数据结构(Ring Buffer),而在这上面均匀分布着槽(Slot),我们的生产者和消费者在某一个时间点都会对应某一个下标的槽,但是,消费者的下标不会越过生产者的下标,这会体现在:如果消费者无法获得下一个可用的槽,则消费者会等待。
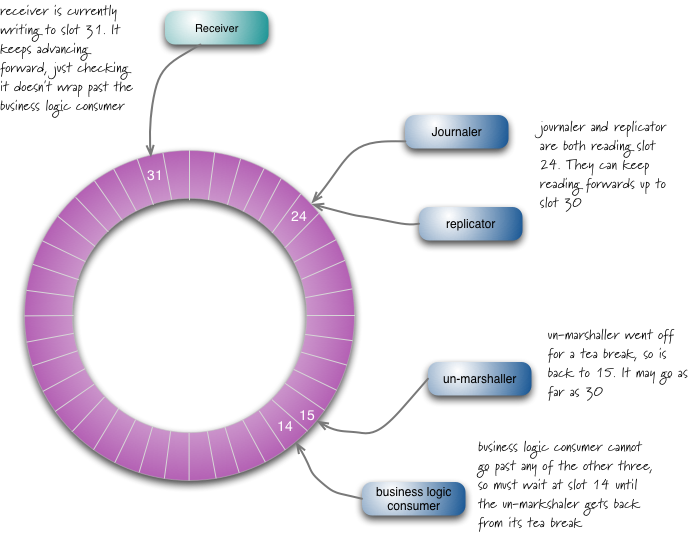
上图就是 LMAX Disruptor 的环形缓冲器的具体结构,图中 Receiver 是消息的生产者,用于收取信息,并写在 Ring Buffer 上;而 Journaler,Replicator,Un-marshaller,Bussiness Logic Consumer 都是信息的消费者。他们之间的规则是:
- 任意对象只能操作自己所在下标的槽
- 任意对象可以看到其他对象所在的下标
另一方面,他们的 sequence(指针)在一定程度上是有次序的,其中 Journaler,Replicator,Un-marshaller 的消费进度不会超过 Receiver,而 Bussiness Logic Consumer 的消费进度不会超过 Un-marshaller(因为 Business Logic Consumer 需要 Un-marshaller 解码后的信息)。因此,如果在运行过程中 15 槽的 Un-marshaller 遇到了处理上的问题,用了较长时间,则 Bussiness Logic Consumer 会等待 Un-marshaller 执行完这个槽的逻辑后,再消费后续槽中的信息。
同时,这也引入了一个问题,如果有消费者落后了 Receiver 太多怎么办?LMAX Disruptor 提供了接口,可以获得后续至多可以消费几个槽的信息,并且使用 batch-read 的方法,大幅提高消息的速度,使得消费者可以很快追上 Receiver 的生产速度,有效杜绝 Receiver 生产过快而等待时间较长的隐患。
LMAX Disruptor 关键算法部分源码实现
首先,了解一下 3.0 源码中的一些类
- RingBuffer:RingBuffer 数据结构,只用于存储数据,更新数据
- 值得注意的是,RingBuffer 把生产者的逻辑包括在了其中(其有 publishEvent 的方法)
- Sequencer: 各生产者 / 消费者的下标控制器,可以获得后续可以使用的 RingBuffer 的槽
- Sequence: 各生产者 / 消费者的当前下标
- EventProcessor: 消費者,其控制着一个 Sequence 对象,通过 Sequence 进行槽中信息的读取
基本的存取逻辑
RingBuffer 基本的存取比较简单,生产者获取下一个可用 slot,获取其中的元素(Event),对元素进行操作,并且发布。
1 | long sequence = ringBuffer.next(); |
next() 方法实现了阻塞的功能,防止出现消费者越过生产者,也防止生产者的进度越过消费者,覆盖了未消费的信息,这个后面可以讲到。
消费者获取槽中的信息:
1 | ("unchecked") |
生产者/消费者下标的边界问题
要实现这样一个数据结构,算法层面上需要解决以下的问题:
- 消费者的消费速度赶上生产者时,消费者需要等待
- 生产者的生产正好到消费者后面时,生产者需要等待
要解决以上问题,需要在 next() 方法里设置等待的条件。通过下面的 next() 的方法源码可以看到具体的实现方法
1 | public long next(int n) { |
可以看到,在获取下一个可用槽的过程中,有一个 GatingSequence 的概念,它是用于防止生产者写完一圈去覆盖了未被消费的信息。一般来说,GatingSequence 是 RingBuffer 上面最后一个 EventProcessor 的 getSequence() 的返回,防止生产者越过最后一个消费者。因此,当自己理想的下一个可用槽大于 GatingSequence 的下标时,则会通过
1 | LockSupport.parkNanos(1L); |
进入等待,该循环直到下一个可用槽被 GatingSequence 释放后才结束。之后,生产者就可以在获取到的可用槽中进行消息的更新。值得注意的是,还有一个 tryNext() 的方法是不阻塞的。
而对于消费者的消费速度赶上生产者的速度的情况:在消费者消费完自己所在的槽的信息后,如要获取下一个可用的槽,则会调用 waitFor 方法,如果目标的 sequence 还没有被生产者 publish,则会继续等待,直到该槽被生产者 publish 方可进入使用。
值得一提的是,对于 Sequencer 的操作都是原子性的,因此不用担心消费者,生产者同时操作的情况,使得有序性得到了保证。
因此,我们可以知道 LMAX Disruptor 使用环形的存储结构,并且基于 Sequence 下标的可见性和原子级操作,有效保证了消费者和生产者之间的有序性,和信息消费的有序性。
Async Logging 中对于 LMAX Disruptor 的使用
说了那么多,那么 Async Logging 如何利用 LMAX Disruptor 的特性,实现异步日志的呢?在启动期间,Log4j 2 会解析 .properties 的文件,并且启动对应名称 logger appender 线程,等待消费者 EventProcessor 把 RingBuffer 中对应的消息取出来,扔到对应的 logger appender 的线程中进行记录。在外部程序触发
1 | logger.info("<Message>"); |
时,log4j 2 库对日志消息进行封装后,调用 AsyncLoggerConfig 的 tryEnqueue 方法去使用自身拥有的 RingBuffer 实例,将最新的日志消息放入下一个可用的 RingBuffer 的槽里面。而 EventProcessor 在没有收到 publish 的时候将会处于 waitFor 的状态,在监听 EventProcessorBarrier 的通知后,会去获取最近的有更新的槽(或者 BatchProcess),并且把获得的消息分配给对应的 appender 线程,并由该线程处理日志信息的打出 / 写入文件的操作。因此可以画出如下的 UML 的图:

这也映证了 Log4j 2 中的异步日志对于日志线程如何获取对应任务的方式出现了变化,其摒弃了传统阻塞队列的模式,而使用了 RingBuffer 无锁队列的模式以达到更为优秀的吞吐量。
性能测试
测试环境 jdk_1.8
测试机器:macOS mojave,处理器:2.3 GHz Intel Core i5,内存: 8 GB 2133 MHz LPDDR3
| logger 类别 | 50 线程,500000 条日志 | 50 线程,1000000 条日志 |
|---|---|---|
| Log4j 1 Sync | 1869 ms | 3552 ms |
| Log4j 2 Sync | 1980 ms | 3691 ms |
| Log4j 1 Async | 1256 ms | 2387 ms |
| Log4j 2 Async | 376.5 ms | 537 ms |
可以看到,在同步日志上面,log4j1 和 log4j2 并没有很大的性能优劣之分;然而,在 log4j 2 主打的异步日志性能上面,出现了很大的提高,快了 log4j 1 的异步日志将近 6 倍,这是由于 log4j 1 的异步日志使用的 ArrayBlockingQueue 的机构,其中的读写竞争,造成了锁的阻塞,损耗了大量的性能。
结论
Log4j 2 主打异步日志模式,其基于 LMAX Disurptor 中的环形缓冲器 RingBuffer 的数据结构,巧妙地解决了异步日志多个日志线程的读写竞争的问题,极大地优化了工程中日志系统的性能,使其较小概率地成为工程中的性能瓶颈。